xCAT HPC Production Readiness and Benchmark HOWTO (WIP)
(Formally known as the xCAT Benchmark HOWTO)
It is generally a good idea to verify that the cluster you just built actually can do work. This can be accomplished by running a few industry accepted benchmarks. The purpose of benchmarking is not to get the best results, but to get consistent repeatable accurate results that are also the best results.
With a goal of "consistent repeatable accurate results" it is best to start with as few variables as possible. I recommend starting with single node benchmarks. e.g. STREAM. If all machines have similar STREAM results, then memory can be ruled out as a factor with other benchmark anomalies. Next work your way up to processor and disk benchmarks, then multinode (parallel) benchmarks, then finally HPL. After each more complicated benchmark runs check for "consistent repeatable accurate results" before continuing.
Outlined below is a recommended path.
Single Node (serial) Benchmarks:
Parallel Benchmarks:
Prerequisites:
Feel free to follow your own path, but please start with the Sanity Checks and Torque IANS.
When analyzing performance anomalies only compare apples-to-apples. Every system setting (BIOS) must be identical. Every hardware setting, configuration, OS, kernel, location of DIMMs, etc... must be identical. Exact clones.
First check that each node per class of node has the same amount of RAM,
e.g.:
psh noderange free | grep Mem: | awk
'{print $3}' | sort | uniq
It is OK to get multiple values as long as they are very close together.
Next check that each node per class of node has the same number of processors,
e.g.:
psh noderange 'cat /proc/cpuinfo | grep
processor | wc -l' | awk '{print $2}' | sort | uniq
Next check that each node per class of node has the same BIOS version, e.g.:
psh -s noderange $XCATROOT'/$(uname
-m)/sbin/dmidecode;echo END' | \
perl -pi -e '$/ = "END\n";' -e 's/.*BIOS
Information\n[^\n]*\n([^\n]*\n).*END/\1/sg' | \
grep Version | awk -F: '{print $3}' | sort | uniq
OR
psh compute $XCATROOT'/$(uname -m)/sbin/dmidecode
| grep Version | head -1' | \
awk -F: '{print $3}' | sort | uniq
To find the offending nodes:
psh -s noderange $XCATROOT'/$(uname
-m)/sbin/dmidecode;echo END' | \
perl -pi -e '$/ = "END\n";' -e 's/.*BIOS
Information\n[^\n]*\n([^\n]*\n).*END/\1/sg' | \
grep Version | sort +2
OR
psh compute $XCATROOT'/$(uname -m)/sbin/dmidecode
| grep Version | head -1' | sort +2
Network Check
No network, no cluster. The stability of the network is critical. As root type:
ppping noderange
Where noderange is a list of all nodes in the queuing system, plus any nodes that users will be submitting jobs from. ppping (parallel parallel ping) is an xCAT utility that will tell each node in the noderange to ping all the nodes in the noderange. No news is good news, i.e. no output is good, only errors will be displayed.
If you have Myrinet, ssh to a Myrinet node and type:
ppping -i myri0 noderange
Where noderange is a list of all Myrinet nodes in the cluster.
Both tests are critical and must succeed, if not, you will never launch a job.
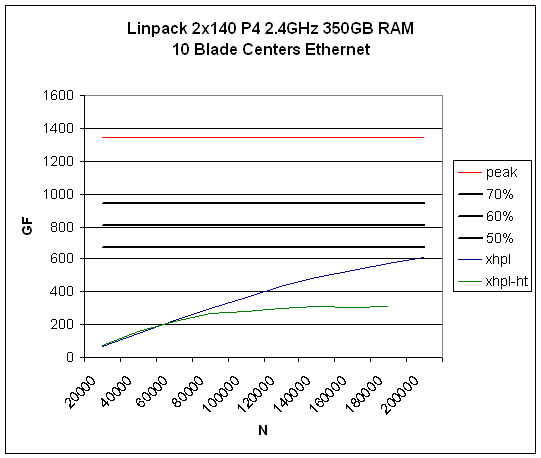
Disable Hyperthreading
Intel P4 and x86_64 Hyperthreading do not aid in the performance of processor
and memory intensive HPC applications--it actually hurts performance.
Illustrated below the HPL benchmark. xhpl (HT disabled) continues to grow
as the problem size increases. xhpl-ht (HT enabled) flattens out as the
problem size increases.
All attempts to leverage HT in HPC applications have failed. E.g. multithreaded libs with OMP.
Never run benchmarks as root. Use the addclusteruser command or equivalent to create a user on your primary user/login node. If you are using NIS you are ready to go. If you are using password synchronization then type:
pushuser noderange username
Where noderange is a list of all nodes in the queuing system, plus any nodes that users will be submitting jobs from.
Verify with psh that all nodes have mounted the correct /home directory and that your added user is visible and that the directory permissions are correct:
psh -s noderange 'ls -l /home | grep username'
Where noderange is a list of all nodes in the queuing system, plus any nodes that users will be submitting jobs from and username is the user you are posing as.
Using pbstop and showq verify that all of your nodes are visible and ready.
Login as your sample user (e.g. bob) and test Torque/Maui.
bob@head01:~> qsub -l
nodes=2,walltime=1:00:00 -I
qsub: waiting for job 0.head01.foobar.org to start
qsub: job 0.head01.foobar.org ready
----------------------------------------
Begin PBS Prologue Thu Dec 19 14:17:53 MST 2002
Job ID: 0.head01.foobar.org
Username: bob
Group: users
Nodes: node10 node9
End PBS Prologue Thu Dec 19 14:17:54 MST 2002
----------------------------------------
Note the Nodes: line.
Try to ssh from node to node and back
to the user node that started qsub:
bob@node10:~> ssh node9
bob@node9:~> exit
logout
Connection to node9 closed.
bob@node10:~> ssh head01
bob@head01:~> exit
logout
Connection to head01 closed.
bob@node10:~> exit
logout
qsub: job 0.head01.foobar.org completed
Now try to ssh back to the
nodes that were assigned, you should be denied:
bob@head01:~> ssh node9
14653: Connection close by 199.88.179.209
It is worth noting that x86_64 and ppc64 architectures can generate and execute 32-bit and 64-bit code. Below is a chart of the options. The default behavior is in bold.
| GNU | Intel | PGI 5.2 | IBM | |
| x86_64 | -m32, -m64 | 32bit: Use i686 compiler. 64bit: Use x86_64 compiler. |
-tp k8-32, -tp k8-64 | n/a |
| ppc64 not SLES8 | -m32, -m64 | n/a | n/a | -q32, -q64 |
| ppc64 SLES8 | 32bit: g?? 64bit: powerpc64-linux-g?? |
n/a | n/a | -q32, -q64 |
The following is the required base software. Benchmark software installation will be covered in the Benchmark section of this document.
For best results use Intel Compilers for IA64 and EM64T, PGI Compilers for x86_64, IBM and GNU for PPC64, and for IA32 use Intel Compilers or PGI. I have also had good results using PGI for just Fortran and GCC 3.3 for C on x86_64. Before building or downloading GCC 3.3 verify that is it not already installed:
rpm -qa | grep gcc
You may need to use the full path to gcc33, e.g.:
/opt/gcc33/bin/gcc
Intel 8.0 Compilers (IA32/IA64)
Intel 8.1 Compilers (EM64T)
PGI 5.2 Compilers (Opteron/IA32)
IBM Compilers (PPC64)
GNU Compilers
Intel Math Kernel Libraries 7.0
(optional)
AMD Core Math Libraries (optional)
ESSL/PESSL (PPC64, optional) WIP
Goto Libraries (required for HPL)
ATLAS Libraries (optional)
MPICH
MPICH-GM
LAM-MPI (optional)
Intel Math Kernel Libraries 7.0
Optimally building ATLAS is beyond the scope of this document, however current binary distributions are available. It is recommended that you try both.
MPICH is a freely available MPI implementation that runs over IP. There are many ways to build MPICH. Free free to build it your way or the xCAT way:
export MPICHROOT=/usr/local/mpich
Usage: mpimaker: [mpich tarball] [up|smp] [compiler] [rsh|ssh|{full path to other}]
Supported Compilers/Architectures:
gnu: i686(32bit), ia64(64bit), x86_64(64bit), ppc64(32bit)
gnu32: x86_64(32bit), ppc64(32bit)
gnu64: x86_64(64bit), ppc64(64bit)
intel: i686(32bit), ia64(64bit), x86_64(64bit)
8.x compiler support only
pgi: i686(32bit)
pgi32: x86_64(32bit)
pgi64: x86_64(64bit)
pgi64gcc: x86_64(64bit) PGI Fortran, GNU gcc
pgi64gcc33: x86_64(64bit) PGI Fortran, GNU gcc33 (SLES8)
pgi64gcc33nogmalloc: x86_64(64bit) PGI Fortran, GNU gcc33 (SLES8)
GM only --with-device=ch_gm:-disable-registration
5.2 compiler support only
absoft64gcc33: x86_64(64bit) Absoft Fortran, GNU gcc33 (SLES8)
nag64gcc33: x86_64(64bit) NAG Fortran, GNU gcc33 (SLES8)
ibmcmp32: ppc64(32bit) IBM VCCPP/XLF
ibmcmp64: ppc64(64bit) IBM VCCPP/XLF
Hint(s):
/opt/xcat/build/mpi/mpimaker mpich-1.2.6..13.tar.gz smp pgi64 ssh
/opt/xcat/build/mpi/mpimaker mpich-1.2.6.tar.gz smp pgi64 ssh
MPICH-GM is a freely available MPI implementation that runs over Myrinet. There are many ways to build MPICH-GM. Free free to build it your way or the xCAT way:
export MPICHROOT=/usr/local/mpich
Usage: mpimaker: [mpich tarball] [up|smp] [compiler] [rsh|ssh|{full path to other}]
Supported Compilers/Architectures:
gnu: i686(32bit), ia64(64bit), x86_64(64bit), ppc64(32bit)
gnu32: x86_64(32bit), ppc64(32bit)
gnu64: x86_64(64bit), ppc64(64bit)
intel: i686(32bit), ia64(64bit), x86_64(64bit)
8.x compiler support only
pgi: i686(32bit)
pgi32: x86_64(32bit)
pgi64: x86_64(64bit)
pgi64gcc: x86_64(64bit) PGI Fortran, GNU gcc
pgi64gcc33: x86_64(64bit) PGI Fortran, GNU gcc33 (SLES8)
pgi64gcc33nogmalloc: x86_64(64bit) PGI Fortran, GNU gcc33 (SLES8)
GM only --with-device=ch_gm:-disable-registration
5.2 compiler support only
absoft64gcc33: x86_64(64bit) Absoft Fortran, GNU gcc33 (SLES8)
nag64gcc33: x86_64(64bit) NAG Fortran, GNU gcc33 (SLES8)
ibmcmp32: ppc64(32bit) IBM VCCPP/XLF
ibmcmp64: ppc64(64bit) IBM VCCPP/XLF
Hint(s):
/opt/xcat/build/mpi/mpimaker mpich-1.2.6..13.tar.gz smp pgi64 ssh
/opt/xcat/build/mpi/mpimaker mpich-1.2.6.tar.gz smp pgi64 ssh
LAM-MPI is a freely available MPI implementation that runs over IP. There are many ways to build LAM-MPI. Free free to build it your way or the xCAT way:
WIP
If you are already familiar with starting and monitoring jobs through Torque/Maui you may still want to read this section to understand how Torque/Maui is setup by xCAT.
Attributes
xCAT and Torque share the same attributes. xCAT attributes are stored in $XCATROOT/etc/nodelist.tab and Torque attributes are stored in /var/spool/pbs/server_priv/nodes. The Torque nodes file is generated by xCAT's makepbsnodefile command.
In this document will assume that you assigned an attribute of ia64 to all IA64 nodes and an attribute of x86 to all ia32/i686 nodes. Examples using the attribute of compute refer to any compute node (ia64 or x86).
It will be necessary to edit supplied Torque scripts with the correct node assignment attributes for your cluster.
Submitting a Job
qsub is the Torque command to submit a
job. Job submission is not allow for root. At a minimum you must
specify how many nodes for how long.
To request (16) IA64 nodes with 2 processors/node, for 10 minutes interactively
and assuming that Torque has ia64 assigned
as an attribute to all the IA64 nodes, type:
$ qsub -l nodes=16:ia64:ppn=2,walltime=10:00 -I
To request 10 nodes of any attribute with 2 processors/node for 24 hours to run your Torque script foobar.pbs, type:
$ qsub -l nodes=10:ppn=2,walltime=24:00:00 foobar.pbs
Monitoring and Job Output
Use the tools pbstop, qstat, and showq to monitor Torque/Maui.
If Torque has the appropriate patches and your home directory contains a .pbs_spool subdirectory, then you can monitor your job stdout and stderr real-time with tail -f. If you do not have this patch applied your output will be in the directory submitted from in the format: jobname.ojobnumber for stdout and jobname.ejobnumber for stderr. You will have to wait for the job to complete before the files will be present.
Torque Help
RTFM.
E.g.
$ man qsub
Advice
For each benchmark run a small test first to test out all the scripts interactively, then a small test through Torque/Maui before submitting larger tests.
E.g. interactively:
$ cd ~/bench/benchmark
$ qsub -l
nodes=2,walltime=1:00:00 -I
qsub: waiting for job 0.head01.foobar.org to start
qsub: job 0.head01.foobar.org ready
----------------------------------------
Begin PBS Prologue Thu Dec 19 14:17:53 MST 2002
Job ID: 0.head01.foobar.org
Username: bob
Group: users
Nodes: node10 node9
End PBS Prologue Thu Dec 19 14:17:54 MST 2002
----------------------------------------
node10:~> cd $PBS_O_WORKDIR
node10:~/bench/benchmark> ./benchmark.pbs
node10:~/bench/benchmark> exit
STREAM
"The STREAM benchmark is a simple synthetic benchmark program that measures
sustainable memory bandwidth (in MB/s) and the corresponding computation rate
for simple vector kernels." --
http://www.cs.virginia.edu/stream/ref.html
IANS, STREAM just bangs on memory. TRIAD results are usually what to look at. STREAM is not a general purpose memory exerciser and utilizes little memory. However if you do have memory anomalies, STREAM can be effected.
STREAM results can be effected by:
When analyzing STREAM output only compare apples-to-apples. Every system setting (BIOS) must be identical. Every hardware setting, configuration, OS, kernel, location of DIMMs, etc... must be identical. Exact clones.
Building and running STREAM:
stream_d results benchmark jobs low high % mean median std dev c_ia64 16 3393.26 3488.88 2.81 3434.70 3441.13 28.74 c_omp_ia64 16 3811.37 3847.14 0.93 3831.52 3836.47 12.51 f_ia64 16 3394.98 3488.65 2.75 3433.98 3440.29 28.07 f_tuned_ia64 16 3390.86 3480.46 2.64 3432.07 3430.85 24.51
The number of jobs should equal the number of nodes even if you specified a ppn > 1. % (max variation from low to high) should be < 5%. Usually for STREAM it is 1-2%. Compiler options can have a large impact on variability and performance. E.g. after changing the optimization level from -O3 to -O2 stability increased, but performance dropped:
stream_d results benchmark jobs low high % mean median std dev c_ia64 16 1038.20 1044.71 0.62 1041.85 1041.93 1.55 c_omp_ia64 16 1980.83 2005.46 1.24 1992.89 1992.90 6.73 f_ia64 16 1038.35 1046.26 0.76 1042.57 1042.57 1.93 f_tuned_ia64 16 1038.84 1044.78 0.57 1041.77 1041.76 1.47
Edit any of the makefiles and rebuild and retest until you get the desired
performance and stability. If you cannot reduce variability to < 5% you
may have non-identical hardware configurations or hardware problems.
Analyze each output file in
~/bench/stream/output to find the
irregularities.
NOTE: NUMA Systems.
Like the STREAM benchmark each node should be identical (cloned) when checking for variability. Consistent STREAM results should be achieved first.
NPB Serial benchmark jobs low high % mean median std dev bt.A 16 1132.79 1142.69 0.87 1139.64 1140.16 2.41 cg.A 16 238.53 241.72 1.33 240.42 240.32 0.74 ep.A 16 21.96 21.99 0.13 21.97 21.99 0.01 ft.A 16 619.41 625.72 1.01 623.12 623.10 1.76 is.A 16 49.17 50.01 1.70 49.82 49.87 0.21 lu.A 16 830.55 859.95 3.53 839.37 836.44 9.15 mg.A 16 1056.95 1069.20 1.15 1062.30 1062.17 3.67 sp.A 16 713.53 719.78 0.87 716.31 716.83 2.01
The number of jobs should equal the n you passed to ./runit n. % (max variation from low to high) should be < 5%. Compiler options can have a large impact on variability and performance.
NPB OpenMP
"The NAS Parallel Benchmarks (NPB)
are a set of 8 programs designed to help evaluate the performance of parallel
supercomputers. The benchmarks, which are derived from computational fluid
dynamics (CFD) applications, consist of five kernels and three
pseudo-applications. The NPB come in several flavors. NAS solicits performance
results for each from all sources." --
http://www.nas.nasa.gov/NAS/NPB
The NAS Serial Benchmarks are the same as the NAS Parallel Benchmarks except
that MPI calls have been replaced with OpenMP calls to run multiple processor on
a shared memory system.
Like the STREAM benchmark each node should be identical (cloned) when checking for variability. Consistent STREAM and NPB Serial results should be achieved first.
NPB OpenMP benchmark jobs low high % mean median std dev bt.A 16 2044.48 2064.61 0.98 2054.67 2054.68 4.60 cg.A 16 418.72 441.48 5.43 429.96 430.39 4.72 ep.A 16 44.43 44.46 0.06 44.45 44.45 0.00 ft.A 16 1042.91 1060.65 1.70 1053.08 1053.53 4.66 lu.A 16 1739.11 1963.40 12.89 1856.81 1873.96 67.51 mg.A 16 1467.50 1506.04 2.62 1486.37 1486.54 11.85 sp.A 16 1087.26 1104.33 1.57 1096.15 1095.74 5.68
The number of jobs should equal the
n you passed to
./runit n.
% (max variation from low to high) should be < 5%, however multiprocessor
tests can have higher variability. You may want to analyze the output and
track down the nodes that are increasing the variability, then rerun. If
variability moves around you don't have a hardware problem, E.g.:
lu.A has a high degree of variability.
$ cd ~/bench/NPB3.0/NPB3.0-OMP/output
$ grep total *lu* | sort +4 -n
lu.A.node012.88.master: Mop/s total = 1739.11 lu.A.node009.91.master: Mop/s total = 1748.24 lu.A.node008.92.master: Mop/s total = 1766.47 lu.A.node005.95.master: Mop/s total = 1800.81 lu.A.node002.98.master: Mop/s total = 1803.29 lu.A.node016.84.master: Mop/s total = 1819.56 lu.A.node007.93.master: Mop/s total = 1850.71 lu.A.node010.90.master: Mop/s total = 1866.03 lu.A.node011.89.master: Mop/s total = 1873.96 lu.A.node004.96.master: Mop/s total = 1899.82 lu.A.node001.99.master: Mop/s total = 1903.54 lu.A.node013.87.master: Mop/s total = 1903.75 lu.A.node006.94.master: Mop/s total = 1914.18 lu.A.node015.85.master: Mop/s total = 1916.82 lu.A.node014.86.master: Mop/s total = 1939.39 lu.A.node003.97.master: Mop/s total = 1963.40
Note that output is evenly disbursed. This
usually indicates software, but not necessarily a problem. Rerun the
benchmark.
$ cd ~/bench/NPB3.0/NPB3.0-OMP/bin
Remove the benchmarks that you do not need to retest.
$ rm bt.A cg.A ...
$ cd ..
$ mv output output1
$ ./runit large n (you want multiple runs/node)
$ cd output
$ grep total *lu* | sort +4 -n | grep node013
lu.A.node013.172.master: Mop/s total = 1683.24 lu.A.node013.161.master: Mop/s total = 1834.06 lu.A.node013.151.master: Mop/s total = 1867.71 lu.A.node013.135.master: Mop/s total = 1943.91
Checking a random node the output varies. Higher variation for this benchmark may be normal. Compiler options can also have a large impact on variability and performance.
"IOzone is a filesystem benchmark tool. The benchmark generates and measures a variety of file operations. Iozone is useful for performing a broad filesystem analysis of a vendor’s computer platform." -- http://www.iozone.org
Like the STREAM benchmark each node should be identical (cloned) when checking for variability. Consistent STREAM and NPB Serial results should be achieved first.
Iozone: Performance Test of File I/O Version $Revision: 3.217 $ Compiled for 64 bit mode. Build: linux-ia64 Contributors:William Norcott, Don Capps, Isom Crawford, Kirby Collins Al Slater, Scott Rhine, Mike Wisner, Ken Goss Steve Landherr, Brad Smith, Mark Kelly, Dr. Alain CYR, Randy Dunlap, Mark Montague, Dan Million, Jean-Marc Zucconi, Jeff Blomberg, Erik Habbinga, Kris Strecker. Run began: Tue Feb 17 20:10:42 2004 File size set to 33554432 KB Record Size 16384 KB Command line used: /home/ibm/bench/iozone/iozone.ia64 -j 1 -t 1 -l 1 -u 1 -L 128 -S 3072 -s 32G -i 0 -i 1 -r 16M Output is in Kbytes/sec Time Resolution = 0.000001 seconds. Processor cache size set to 3072 Kbytes. Processor cache line size set to 128 bytes. File stride size set to 1 * record size. Min process = 1 Max process = 1 Throughput test with 1 process Each process writes a 33554432 Kbyte file in 16384 Kbyte records Children see throughput for 1 initial writers = 59938.48 KB/sec Parent sees throughput for 1 initial writers = 45289.51 KB/sec Min throughput per process = 59938.48 KB/sec Max throughput per process = 59938.48 KB/sec Avg throughput per process = 59938.48 KB/sec Min xfer = 33554432.00 KB Children see throughput for 1 rewriters = 69368.87 KB/sec Parent sees throughput for 1 rewriters = 48407.56 KB/sec Min throughput per process = 69368.87 KB/sec Max throughput per process = 69368.87 KB/sec Avg throughput per process = 69368.87 KB/sec Min xfer = 33554432.00 KB Children see throughput for 1 readers = 59893.57 KB/sec Parent sees throughput for 1 readers = 59893.49 KB/sec Min throughput per process = 59893.57 KB/sec Max throughput per process = 59893.57 KB/sec Avg throughput per process = 59893.57 KB/sec Min xfer = 33554432.00 KB Children see throughput for 1 re-readers = 59999.96 KB/sec Parent sees throughput for 1 re-readers = 59999.85 KB/sec Min throughput per process = 59999.96 KB/sec Max throughput per process = 59999.96 KB/sec Avg throughput per process = 59999.96 KB/sec Min xfer = 33554432.00 KB
Do this for each file system you plan to test. Record the total time.
iozone results benchmark nodes low high % mean median std dev /tmp(w) 100 16.34 49.14 200.73 44.00 44.80 3.85 /tmp(r) 100 36.90 41.65 12.87 38.63 38.82 1.44 /scr/PBS(w) 100 55.90 70.70 26.47 64.35 64.33 1.13 /scr/PBS(r) 100 57.62 65.13 13.03 59.07 59.05 0.76
This analyze script only reports sequential block read and write performance
in K/s. The number of jobs should equal the number of nodes even if you
specified a ppn > 1.
% (variation from low to high) varies from file system to file system.
The number of operations/second is much smaller that the number of
operations/second for a processor or memory benchmark. This may increase
variability. The type of operations for I/O are also more complex.
This may also increase variability.
In the example above /tmp is on the
system disk with swap. iozone uses all memory and will increase swap
usage. It is possible that may create anomalies when benchmarking a system
disk. The /scr file system
however has reduced variability. The mean and the median are very similar
and close to center between low and high indicating a possible even distribution
as illustrated:
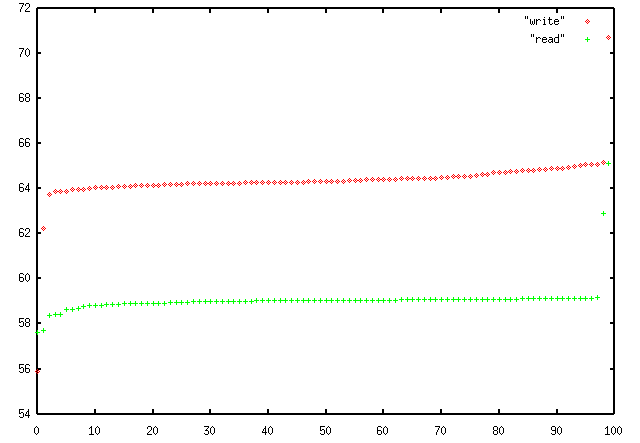
There are a few anomalies that should be checked. View the raw data in
cd ~/bench/iozone/output. Rerun
for that node only if desired.
Ping-Pong is a simple benchmark that measures latency and bandwidth for different message sizes. There are many ping-pong benchmarks available. The origin of the pingpong.c included with xCAT is unknown.
pingpong benchmark jobs low high % mean median std dev latency 8 11.74 11.79 0.42 11.76 11.77 0.02 4000.bw 8 64.90 65.00 0.15 64.97 65.00 0.04 8000.bw 8 85.40 85.50 0.11 85.46 85.50 0.05 16000.bw 8 100.50 100.60 0.09 100.52 100.50 0.04 32000.bw 8 163.40 163.50 0.06 163.43 163.40 0.05 64000.bw 8 191.70 191.90 0.10 191.81 191.80 0.06 128000.bw 8 209.80 209.90 0.04 209.85 209.90 0.05 256000.bw 8 219.20 219.40 0.09 219.30 219.30 0.05 512000.bw 8 224.40 224.60 0.08 224.46 224.50 0.07 1024000.bw 8 227.30 227.50 0.08 227.40 227.40 0.05 2048000.bw 8 229.70 229.80 0.04 229.75 229.80 0.05The number of jobs should = 1/2 of nodes= in pingpong.pbs even if you specified a ppn > 1. % (variation from low to high) should be < 5%. If you cannot reduce variability to < 5% you may have non-identical hardware configurations, hardware, or software problems. Analyze each output file in ~/bench/pingpong/output to find the irregularities. Rerun tests manually to validate software or hardware irregularities.
Pallas MPI Benchmark (PMB) provides a concise set of benchmarks targeted at measuring the most important MPI functions.
Like the STREAM benchmark each node should be identical (cloned) when checking for variability. Consistent STREAM, NPB Serial, and Ping-Pong results should be achieved first.
Download PMB2.2.1 from
http://www.pallas.com/e/products/pmb and save to
/tmp, then extract in
~/bench/PMB.
$ cd ~/bench/PMB
$ tar zxvf /tmp/PMB2.2.1.tar.gz
Build:
$ cd
~/bench/PMB2.2.1/SRC_PMB
$ cp -f Makefile.xcat Makefile
$ make clean
$ make
$ cp PMB-MPI1 ../..
Edit pmb.pbs and correct
the settings for the Torque command options (usually just the attributes).
nodes should = as many nodes you want
to test, and
ppn should = the total number of
processors in the node (usually =2). The walltime
should be very large for a large cluster. 24 hours is good. Edit
the MPICH
environmental variable for the location of MPICH.
Manual test:
$ cd ~/bench/PMB
$ qsub -l nodes=2:compute:ppn=2,walltime=1:00:00 -I
$ cd $PBS_O_WORKDIR
$ ./pmb.pbs
Check pbm.2x2.out for errors.
Submit:
$ cd ~/bench/PMB
$ qsub pmb.pbs
Analyze. Check the pbm*.out file for errors. The purpose of this test is to validate that it runs and that there are no problems with MPI.
"The NAS Parallel Benchmarks (NPB) are a set of 8 programs designed to help evaluate the performance of parallel supercomputers. The benchmarks, which are derived from computational fluid dynamics (CFD) applications, consist of five kernels and three pseudo-applications. The NPB come in several flavors. NAS solicits performance results for each from all sources." -- http://www.nas.nasa.gov/NAS/NPB
Like the STREAM benchmark each node should be identical (cloned) when checking for variability. Consistent STREAM and NPB Serial results should be achieved first and PMB should pass.
NPB MPI benchmark jobs low high % mean median std dev bt.C.16 8 4962.76 5019.85 1.15 5001.53 5009.26 19.22 cg.C.16 8 2099.15 2206.02 5.09 2168.93 2193.77 38.09 ep.C.16 8 351.20 352.30 0.31 352.01 352.29 0.47 ft.C.16 8 3875.62 4082.68 5.34 3994.40 4047.88 79.27 is.C.16 8 132.17 144.62 9.41 139.09 141.56 4.95 lu.C.16 8 12285.40 12461.64 1.43 12382.44 12388.76 50.90 mg.C.16 8 9305.53 9711.40 4.36 9449.80 9462.39 131.44 sp.C.16 8 4373.73 4457.04 1.90 4434.64 4448.91 28.32
The number of jobs should equal the
n you passed to
./runit n.
% (variation from low to high) should be < 5%, however multiprocessor
and multinode tests can have higher variability. You may want to analyze the output and
track down the jobs that are increasing the variability, then rerun. If
variability moves around you don't have a hardware problem. Higher variation for this benchmark may be normal. Compiler options
can also have a large impact on variability and performance.
In this example is.C.16 has high
variability, it also ran in < 10 seconds on IA64. This benchmark may be
too small to get consistency, and unfortunately the
is benchmark does not have a larger
(class D) problem size.
"HPL is a software package that solves a (random) dense linear system in double precision (64 bits) arithmetic on distributed-memory computers. It can thus be regarded as a portable as well as freely available implementation of the High Performance Computing Linpack Benchmark." -- http://www.netlib.org/benchmark/hpl
Like the STREAM benchmark each node should be identical (cloned) when checking for variability. Consistent STREAM and NPB Serial and Parallel results should be achieved first and PMB should pass.
Support
Egan Ford
egan@us.ibm.com
August 2004